
rueki
토픽 모델링 - 잠재 디리클레 할당(Latent Dirichlet Allocation) 본문
잠재 디리클레 할당(LDA)은 토픽 모델링의 대표적 알고리즘으로서,
문서들은 토픽들의 혼합으로 구성되어져 있으며, 토픽들은 확률 분포에 기반하여 단어들을 생성한다고 가정한다.
문서1 : 저는 사과랑 바나나를 먹어요
문서2 : 우리는 귀여운 강아지가 좋아요
문서3 : 저의 깜찍하고 귀여운 강아지가 바나나를 먹어요
LDA를 수행할 때 문서 집합에서 토픽이 몇 개가 존재할 지 가정하는 것은 사용자가 해야한다.
토픽의 개수 K를 2라고 가정하고 LDA를 수행했다고 할 때,
<각 문서의 토픽 분포>
문서1 : 토픽 A 100%
문서2 : 토픽 B 100%
문서3 : 토픽 B 60%, 토픽 A 40%
<각 토픽의 단어 분포>
토픽A : 사과 20%, 바나나 40%, 먹어요 40%, 귀여운 0%, 강아지 0%, 깜찍하고 0%, 좋아요 0%
토픽B : 사과 0%, 바나나 0%, 먹어요 0%, 귀여운 33%, 강아지 33%, 깜찍하고 16%, 좋아요 16%
위와 같이 추정될 수가 있다.
LDA는 문서의 집합으로부터 어떤 토픽이 존재하는지를 알아내기 위한 알고리즘이다.
빈도 수 기반의 표현방법인 Bow의 행렬 DTM 또는 TF-IDF 행렬을 입력으로 하는데,
LDA는 단어의 순서를 신경쓰지 않는다.
1) 문서에 사용할 단어의 개수 N을 정합니다.
- Ex) 5개의 단어를 정하였습니다.
2) 문서에 사용할 토픽의 혼합을 확률 분포에 기반하여 결정합니다.
- Ex) 위 예제와 같이 토픽이 2개라고 하였을 때 강아지 토픽을 60%, 과일 토픽을 40%와 같이 선택할 수 있습니다.
3) 문서에 사용할 각 단어를 (아래와 같이) 정합니다.
3-1) 토픽 분포에서 토픽 T를 확률적으로 고릅니다.
- Ex) 60% 확률로 강아지 토픽을 선택하고, 40% 확률로 과일 토픽을 선택할 수 있습니다.
3-2) 선택한 토픽 T에서 단어의 출현 확률 분포에 기반해 문서에 사용할 단어를 고릅니다.
- Ex) 강아지 토픽을 선택하였다면, 33% 확률로 강아지란 단어를 선택할 수 있습니다. 이제 3)을 반복하면서 문서를 완성합니다.
LDA는 토픽을 뽑아내기 위하여 위 과정을 역으로 추적하는 역공학을 수행한다.
LDA의 수행과정에 대해 알아보자
1) 사용자는 알고리즘에게 토픽의 개수 k를 알려준다
LDA에게 토픽 개수를 알려주는 역할은 사용자가 해야한다.
토픽의 개수 k를 입력받으면, k개의 토픽이 M개의 전체 문서에 걸쳐 분포되어 있다고 가정한다.
2) 모든 단어를 k개 중 하나의 토픽에 할당한다.
모든 문서의 모든 단어에 대해 k개 중 하나의 토픽을 랜덤으로 할당한다.
작업 이후에, 각 문서는 토픽을 가지며, 토픽은 단어 분포를 가지는 상태이다.
*랜덤 할당을 하면 결과는 원래 전부 틀린 상태이다
3) 모든 문서의 모든 단어에 대해 아래 사항 반복 진행
3-1) 어떤 문서의 각 단어 w는 자신은 잘못된 토픽에 할당되어져 있지만, 다른 단어들은 전부 올바른 토픽에 할당되어져 있는 상태라고 가정합니다. 이에 따라 단어 w는 아래의 두 가지 기준에 따라서 토픽이 재할당된다.
- p(topic t | document d) : 문서 d의 단어들 중 토픽 t에 해당하는 단어들의 비율
- p(word w | topic t) : 단어 w를 갖고 있는 모든 문서들 중 토픽 t가 할당된 비율
이를 반복하면, 모든 할당이 완료된 수렴 상태가 됩니다. 두 가지 기준이 어떤 의미인지 예를 들어보겠습니다. 설명의 편의를 위해서 두 개의 문서라는 새로운 예를 사용합니다.
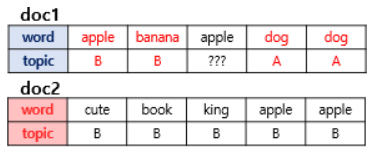
doc1에서 apple의 토픽을 정하고자한다. doc1의 모든 단어들이 A와 B에 50:50의 비율로 할당되어져 있으므로,
apple은 어디에도 속할 가능성이 있다.
다른경우가 있다.

전체 문서에서 토픽 할당을 봤을 때, apple은 전부 B에 할당되있는 것을 볼 수 있으므로
doc1의 3번째 apple의 토픽은 B로 볼 수가 있다.
***
LSA : DTM을 차원 축소 하여 축소 차원에서 근접 단어들을 토픽으로 묶는다.
LDA : 단어가 특정 토픽에 존재할 확률과 문서에 특정 토픽이 존재할 확률을 결합확률로 추정하여 토픽을 추출한다.
'DL > NLP' 카테고리의 다른 글
| 워드투벡터(Word2Vec) (0) | 2019.07.04 |
|---|---|
| 워드 임베딩 (0) | 2019.07.04 |
| 토픽 모델링 - 잠재 의미 분석(Latent Semantic Analysis, LSA) (0) | 2019.07.03 |
| 문서 유사도 - 그 외의 유사도 기법들 (0) | 2019.07.03 |
| 문서 유사도 - 코사인 유사도(Cosine Similarity) (0) | 2019.07.03 |



