
rueki
Week11 Deployment & Monitoring part2 본문
Model Monitoring
모델을 배포하고 나면 다 끝난 줄 알았는데, 더 중요한 작업이 있었다.
Monitoring인데 이것을 왜 해줘야 할까? 이유는 배포하고도 배포할 당시의 성능을 계속 유지하기 위해서이다.
배포하고나서 성능이 계속 떨어지는 경우가 있는데 이에 대한 예시가 아래의 그림에 설명이 자세히 되어 있다.

- Data drift : upstream process의 변경과 같이 모델 성능 저하를 일으키는 입력 데이터의 변경.
- Model drift : 모델의 변화로 인한 입출력 사이의 관계가 변화하게 됨.
- Concept drift : 모델링 대상의 통계적 특성이 바뀌는 현상.
- Domain shift : 데이터 셋 분포와 훈련 데이터 셋 간의 변화.
Data drift의 종류
- Instantaneous drift : 데이터가 아예 바뀜으로써 도메인이 변화하거나 process의 변화가 일어나게 됨.

- Gradual drift : 시간의 변화에 따라 데이터의 가치가 변함에 따라 도메인 변화가 일어날 수 있음.

- Periodic drift : 특정 기간에 한해서만 데이터의 특성이 변화함. (Ex. 계절 요인)

- Temporary drift : 순간적인 변화로 인해서 어떤 요인으로 drift가 발생 되었는지 파악하기 어려움.
모니터링 우선순위

Model 성능이 결국 ML system에 전반적으로 영향을 끼치는 중요한 metric이지만 이를 실시간으로 계속 받아내기에는 어려움이 따른다. 그래서 상황에 맞춰서 metric 우선순위를 정하여 고려를 해야한다.
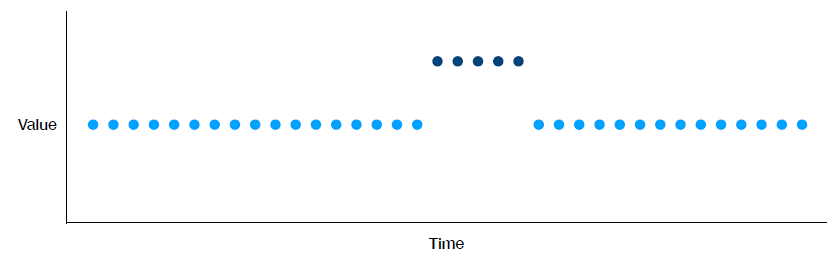
Metric을 측정할 때, Window를 정해서 data의 일부분마다 측정해서 성능을 내보이는데, 보편적으로 많이 사용된 개념 중 하나가 sliding window를 통해서 해당 구간마다의 data에 대한 성능을 계산한다.
- rule-based distance metric
: 통계 정보를 이용해서 단편적으로 측정할 수 있는 metric
- Statistical metric
: 통계학 관점에서의 분석이 들어간 metric 측정
1. KL - Divergence : 서로 다른 데이터 분포간의 거리를 측정하는데 흔히 사용. 각 분포의 log ratio를 계산.
https://angeloyeo.github.io/2020/10/27/KL_divergence.html
KL divergence - 공돌이의 수학정리노트
angeloyeo.github.io
2. KS Statistic(Kolmogorov-Smirnov)
: 누적확률분포 간의 최대 거리로 정의
3. D1 distance
: 확률 밀도 함수 간의 차이의 합으로 정의
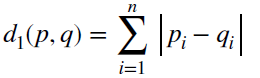
ML에서 모니터링이 중요한 이유
: 일반적인 SW의 경우에는 버그 발생으로 인해서 이를 수정하면 성능 개선이 확실함.
그러나 ML에서는 성능의 저하로 보여지기 때문에, 수정을 안 할 경우, 지속된 성능 저하가 보이게 되기 때문에
Monitoring이 중요함.

데이터와 모델을 매핑시킴에 따라 데이터의 변경에 대해서도 모델도 즉각적으로 조치를 쥐할 수 있게 됨으로써,
효율적으로 System을 관리 할 수가 있다.
'MLOPS > full stack deep learning review' 카테고리의 다른 글
| Week12. Research Directions (0) | 2021.11.27 |
|---|---|
| Week11 Deployment & Monitoring part1 (0) | 2021.11.18 |
| Week 8. Data Management (0) | 2021.10.28 |
| Week 7. Troubleshooting Deep Neural Networks (0) | 2021.10.21 |
| week6. Infrastructure & Tooling (0) | 2021.10.11 |
