
rueki
카운트 기반 단어 표현 - TF-IDF 본문
TF-IDF(Term Frequency-Inverse Document Frequency)는 DTM(문서 단어 행렬) 내에
각 단어에 대한 중요도를 계산할 수 있다.
기존의 DTM 사용보다 정확하게 문서 비교가 가능하다.
TF-IDF(단어 빈도-역 문서 빈도)는 DTM 내의 각 단어들마다 중요정도를 가중치로 준다.
순서로는 DTM을 만들고 TF-IDF를 주면 된다.
문서의 유사도, 검색 시스템에서 검색 결과의 중요도를 정하는 작업, 문서 내 특정 단어의 중요도를
구하는 작업 등에 쓰일 수 있다.
TF-IDF는 TF와 IDF를 곱한 값으로서,
문서 : d
단어 : t
문서 총 갯수 : n
tf(d,t) : 특정 문서 d에서의 특정 단어 t의 등장 횟수
= DTM의 각 단어들이 가진 등장 빈도
df(t) : 특정 단어 t가 등장한 문서의 수
특정 단어 t가 등장한 문서의 수에만 관심을 가진다.
바나나가 문서2, 3에 등장했을 때 바나나의 df는 2이다.
idf(d,t) : df(t)에 반비례하는 수

IDF를 DF의 역수로 사용시에 문서 수 n이 커질 수록 IDF는 기하급수적으로 커진다.
그래서 log사용
앞에서 사용한 DTM문서를 가지고 IDF를 나타내보자
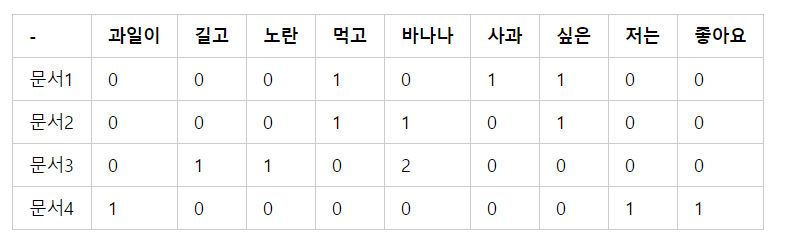

문서의 수는 4이기 때문에 분자는 4로 동일하다.
단어가 등장한 문서의 개수가 늘 수록 가중치는 낮아진다.
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['you know I want your love',
'I like you',
'what should I do',]
vector = CountVectorizer()
print(vector.fit_transform(corpus).toarray())
print(vector.vocabulary_)[[0 1 0 1 0 1 0 1 1]
[0 0 1 0 0 0 0 1 0]
[1 0 0 0 1 0 1 0 0]]
{'you': 7, 'know': 1, 'want': 5, 'your': 8, 'love': 3, 'like': 2, 'what': 6, 'should': 4, 'do': 0}첫 번째 열 인덱스는 'do'이다. 순서는 할당된 인덱스 넘버의 단어 순서다.
사이킷런에서는 TF-IDF를 자동계산해주는 TfidVectorizer를 제공한다.
from sklearn.feature_extraction.text import TfidfVectorizer # TD-IDF 계산
corpus = ['you know I want your love',
'I like you',
'what should I do',]
tfidfv = TfidfVectorizer().fit(corpus)
print(tfidfv.fit_transform(corpus).toarray())
print(tfidfv.vocabulary_)[[0. 0.46735098 0. 0.46735098 0. 0.46735098
0. 0.35543247 0.46735098]
[0. 0. 0.79596054 0. 0. 0.
0. 0.60534851 0. ]
[0.57735027 0. 0. 0. 0.57735027 0.
0.57735027 0. 0. ]]
{'you': 7, 'know': 1, 'want': 5, 'your': 8, 'love': 3, 'like': 2, 'what': 6, 'should': 4, 'do': 0}사이킷 런을 통해서 TF-IDF 가중치에 대해 구하였다..
'DL > NLP' 카테고리의 다른 글
| 문서 유사도 - 그 외의 유사도 기법들 (0) | 2019.07.03 |
|---|---|
| 문서 유사도 - 코사인 유사도(Cosine Similarity) (0) | 2019.07.03 |
| 카운트 기반 단어 표현 - 문서 단어 행렬(Document-Term Matrix, DTM) (0) | 2019.07.02 |
| 카운트 기반 단어 표현 - Bag of Words(Bow) (0) | 2019.07.02 |
| 단어의 표현 (0) | 2019.07.02 |


