
rueki
Week 3. RNN(Recurrent neural network) 본문
Sequence data를 다루기 위해서 등장한 network로 순환 신경망이라고도 한다.
Sequence data 예시 : 텍스트 문장, 주가 데이터..
1. Sequence data 정의: 일정한 구간 및 시간에 따라 수집한 순차적 data를 정의한다.
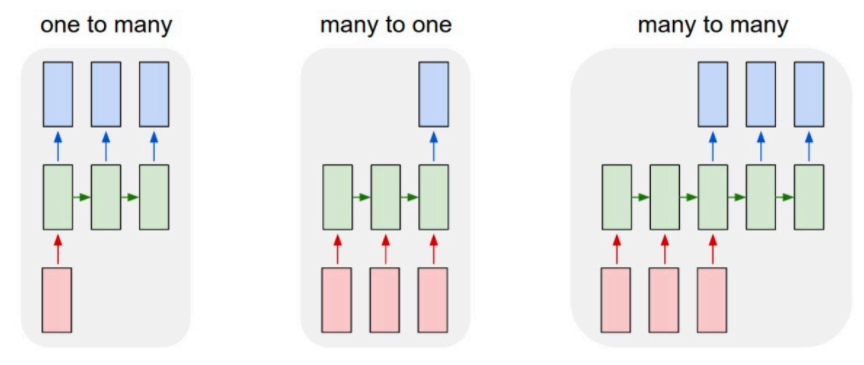
Task 예시 : Sentiment analyisis(Many to one)
translation(Many to many)
Image captioning(One to Many)
2. Sequence data에 feedforward Network를 사용하지 않는 이유
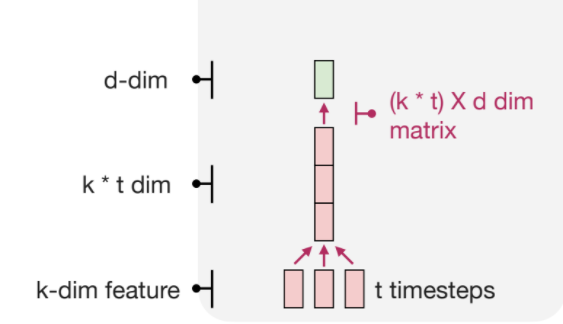
a) Variable length input
Sequence data의 경우 데이터의 길이가 고정적이지 않아서, input마다 다른 길이를 가지게 된다.

여러개의 input이 존재하는데 이를 네트워크에 넣을 때 concat을 하게 되는데,
데이터 length가 짧다면 학습에 무리가 없지만, 예를 들어 길이가 512가 된다면,
input 차원이 결국 512가 되어 버리기때문에 네트워크 안에서 계산해야 할 양이
많아지게 된다.
b) Memory Scailing
Time step이 길어도 최대 길이를 맞춰서 길이가 짧은 데이터여도 다 같은 길이로 맞춰줄 수 있지만,
위에서 언급한대로, timesteps가 길어질 수록, 연산해야 할 양은 그에 비례해서 linear하게 증가하게 되어버린다.
2. RNN
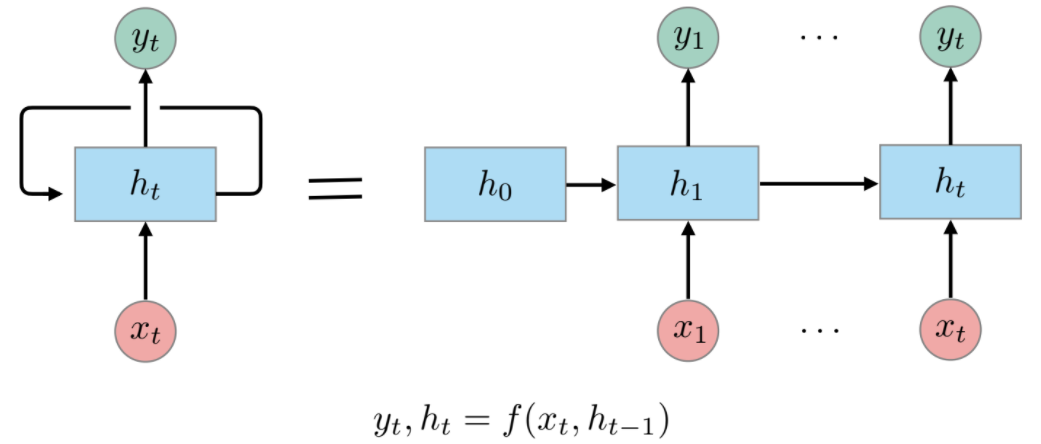
x_t과 이전 hidden state h_(t-1)을 통해서 현재의 hidden state를 update 하는 방식으로
states를 유지할 수 있다는 장점이 있다.
$h_t = tanh(W_{x}x_{t} + W_{h}h_{t-1} + b)$
$y_{t} = f(W_{y}h_{t} + b)$
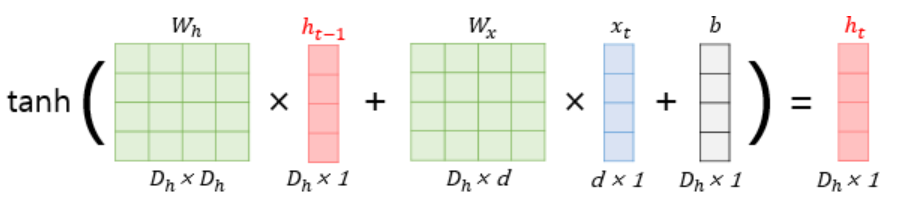
RNN의 문제점
a) long term denpendency

이전 state를 계속 반영해서 sequence data를 fully connected layer보다 그 성질을 유지할 수 있지만,
위의 예시에서 나와있듯이, encoder decoder 구조에서 encoder의 output을 decoder의 input으로
들어가게 되는데, encoder에서의 모든 정보가 하나의 hidden state vector로 넘어가게 되어서, 어떤 정보가
각각 중요한 부분인지 decoder에서 반영되기 어렵다.
b) Vanishing gradient

activation으로 tanh를 사용했을 때 미분값이 0 ~ 1 사이의 범위를 갖게 되는데, 역전파시 기울기 update가
time step만큼 계속 하게 된다면 결국 값이 0에 수렴하게 된다. 이렇게 된다면, 먼 step에 해당되는 state를 충분히 학습하지 못 하게 된다.
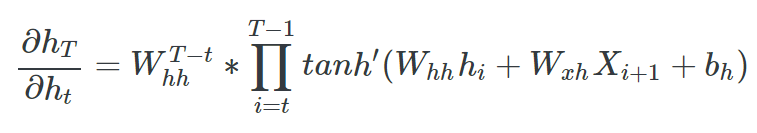
3. LSTM (Long - short Term memory)

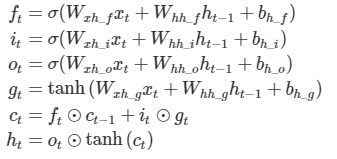
- forget gate
- input gate
- update gate
- output gate
1) forget gate
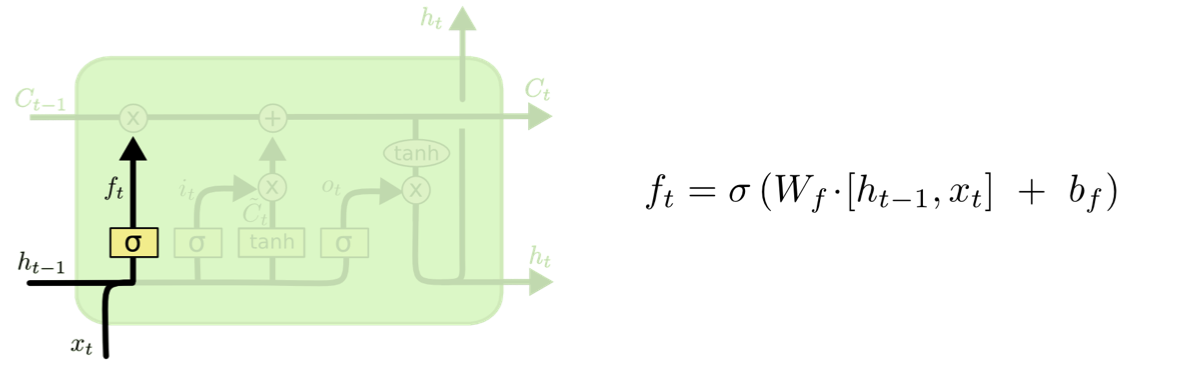
필요하지 않은 정보는 잊어버리겠다라는 맥락에서 나온 gate이다.
활성화 함수로 시그모이드를 사용해서, 0일경우에는 cell state가 0이면 아무 영향이 없는 것이고,
1일 경우에는, 미래의 결과에 영향을 주도록 Cell state 를 그대로 보내도록 유지한다.
2) input gate

현재의 정보를 이용할 지 말지를 정하는 gate이다.
이전 hidden state와 현재의 입력을 받아서 시그모이드를 취하고,
별개로 같은 입력을 tanh를 취해주어 연산한 값이 input gate가 내보내는 값이 된다.
3) update gate
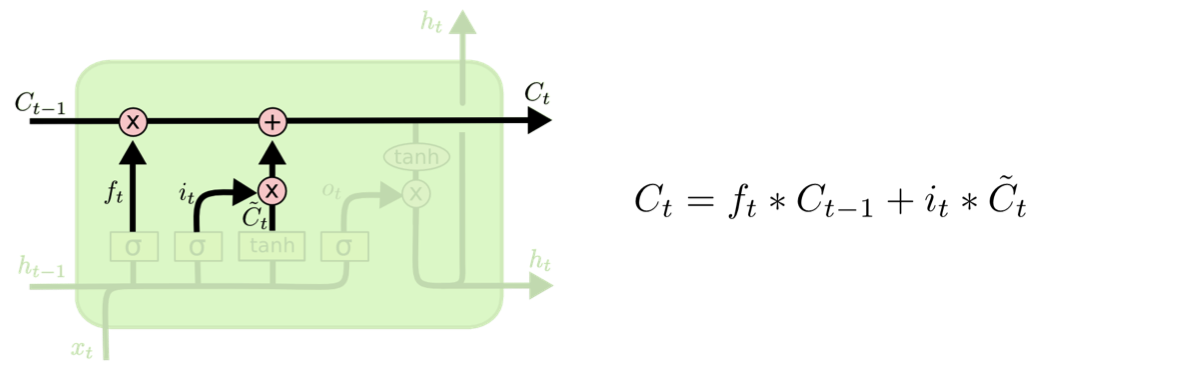
과거의 cell state를 새로운 cell state로 업데이트 하는 과정이다.
4) Output gate
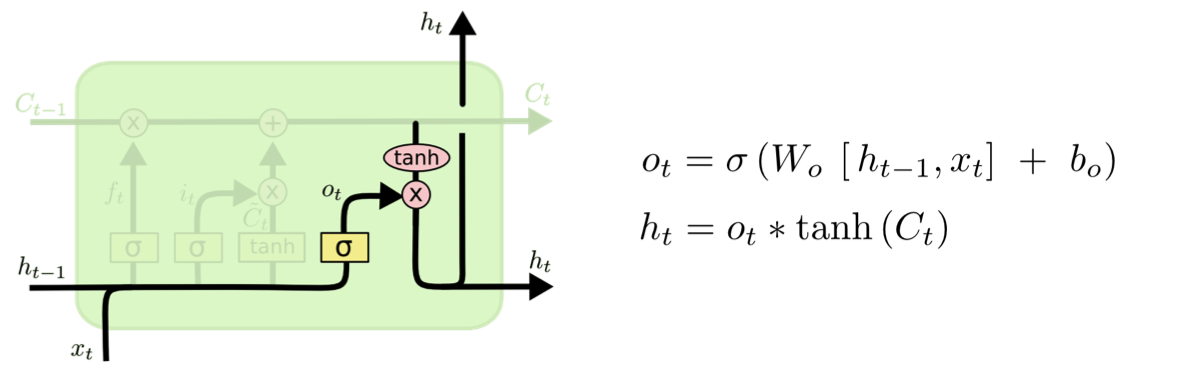
출력값으로 무엇을 내보낼지 결정하는 gate이다.
4. Attention
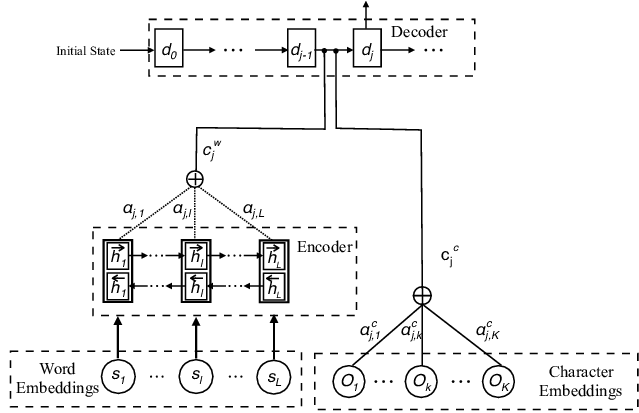
RNN과 다르게 Attention을 통해서 Decoding step에서 어떠한 부분에 집중할 수 있다는 장점이 있다.

RNN 계열 네트워크의 장단점
장점 : Sequence data를 잘 다룰 수 있다.
단점 : 병렬적으로 훈련하기가 힘들기때문에, 많이 느리다.
'MLOPS > full stack deep learning review' 카테고리의 다른 글
| Week 8. Data Management (0) | 2021.10.28 |
|---|---|
| Week 7. Troubleshooting Deep Neural Networks (0) | 2021.10.21 |
| week6. Infrastructure & Tooling (0) | 2021.10.11 |
| Self-Attention, Transformer (0) | 2021.09.29 |
| Week2. CNN (0) | 2021.09.25 |