
rueki
Week 7. Troubleshooting Deep Neural Networks 본문
Week 7. Troubleshooting Deep Neural Networks
륵기 2021. 10. 21. 23:59딥러닝 모델을 훈련하면서, 실질적으로 모델이 잘 학습되는 경우는 드물다. 원하는 task를 해결하기 위해서 결국 에러를 한번쯤은 직면할 수 밖에 없는데, 이번 주차에서는 우리의 모델을 어떻게 피드백을 해야하는지에 대한 내용이다.

모델 구성에 있어서 구현하는 부분은 20프로 정도밖에 차지하지 않는다고 한다.
그 외적인 부분은 전부 디버깅하고 튜닝하는데 투자를 한다.
그렇다면 논문에서 소개되는 성능과 다르게 왜 우리의 모델 성능은 나쁜가에 대해서 알아보아야한다.

첫 번째로 언급할 2가지 이슈는 구현 문제와 파라메터 선택이 있다.
구현 문제는 쉽게 얘기하면 코드 작성 오류로 볼 수가 있다. 오픈 소스 및 모델을 가지고 와서 보통 사용을 하게 될텐데, 가지고온 모듈 및 패키지에 추가로 작성한 우리의 코드가 맞물리지 않아서 구현 오류 및 성능 저하가 일어날 수 있고, 하이퍼 파라메터는 모델 학습에 있어 매우 sensitive한 부분이기에 조금만 달라져도 성능이 크게 변할 수가 있다.

위의 예시는 learning rate의 값에 따라 loss가 어떻게 변하는 지에 대한 그래프인데 학습에 있어서 적절한 learning rate를 선택하는 것이 중요하다.
다음으로 언급할 다른 2가지 이슈는 Data의 적합성 및 데이터셋 구조이다.
실전에서 모델이 좋은 성능을 내보이려면 결국 데이터셋이 충분히 있어야하는데 현실은 그렇지 못하다.
데이터 셋 구축의 문제로는 아래와 같은 이슈들이 있다.
- 충분치 않은 데이터
- 클래스 불균형
- noise data and label
- train set과 test set의 분포가 다름
이러한 문제들을 계속 직면하기 때문에, trouble shooting이 중요하지만, 실제로는 어디서 버그가 발생하는지 찾기 힘들며, 하이퍼 파라메터의 미세한 변화에도 결과는 달라지고, 성능 저하에도 다양한 원인이 있어서 답을 찾기가 힘들다.
그래서 아래의 flow대로 trouble shooting을 한다고 한다.

처음에 시작할 때는 간단하게 시작하는 것을 권장한다.
데이터의 특성에 따라서 처음부터 엄청 복잡한 모델을 사용하지 말고, 기초적인 모델부터 사용해서 점점 해결해나가는 방향으로 나가야 한다.

모델에 대해서 정의를 했다면, 그 다음으로는 기본 설정 (예 : 하이퍼파라메터)을 전반적으로 많이 사용하는 것들로 설정하여서 수정해나가는 것이다.

모델과 학습적인 부분에서 설정을 하고, 데이터를 정규화해서 scale을 맞춰주도록 한다.
마지막으로 풀고자 하는 문제를 최대한 간소화하도록 한다. (작은 데이터 셋부터 시작, 이미지 사이즈 및 클래스 수 고정 등)
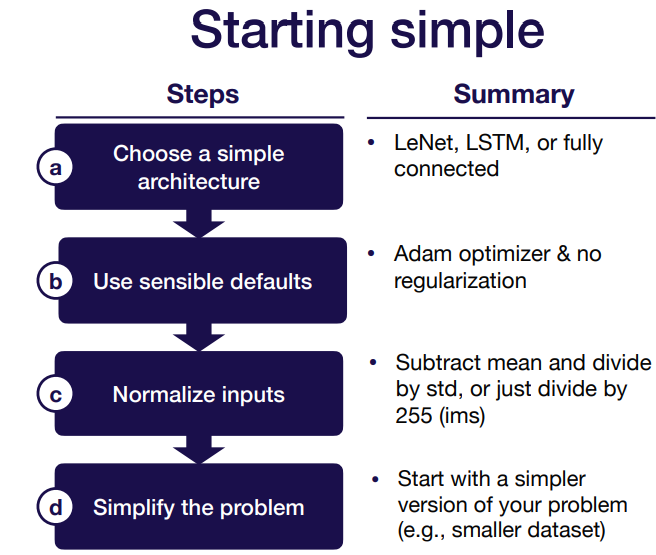
위와 같은 flow로 문제 해결의 시작을 하게 되는데, 딥러닝에서 흔하게 범하는 error는 아래와 같은데 훈련할 때 체크하여 디버깅하는 것을 권장한다.
- 데이터 shape 오류
- 전처리 후 input 에러
- loss function 계산을 위한 입력값들의 오류
- train setting 에러
- nan 값과 같은 numerical instability
이런 것들을 알아채고 해결하기 위해서는 디버깅을 해야하는데, 모델을 처음 돌릴 때는 아래의 그림에 나와있는 사항들을 체크해보자. 데이터의 특성 및 하드웨어적인 부분을 고려하지 않을 때 흔히 발생하는 것들인것 같다.

- Shape mismatch, Casting issue
직접 데이터 shape을 찍어보며 input 및 output을 체크해보고, 또한 casting이 일관되게 되어 있는지 확인해야 한다.
사전에 float 타입으로 바꾸는 것을 기억해두자.
- Out of Memory
데이터가 너무 많은 경우, 텐서 차원기 고차원인 경우, gpu 메모리가 부족한 경우 등 다양한 문제가 있다.
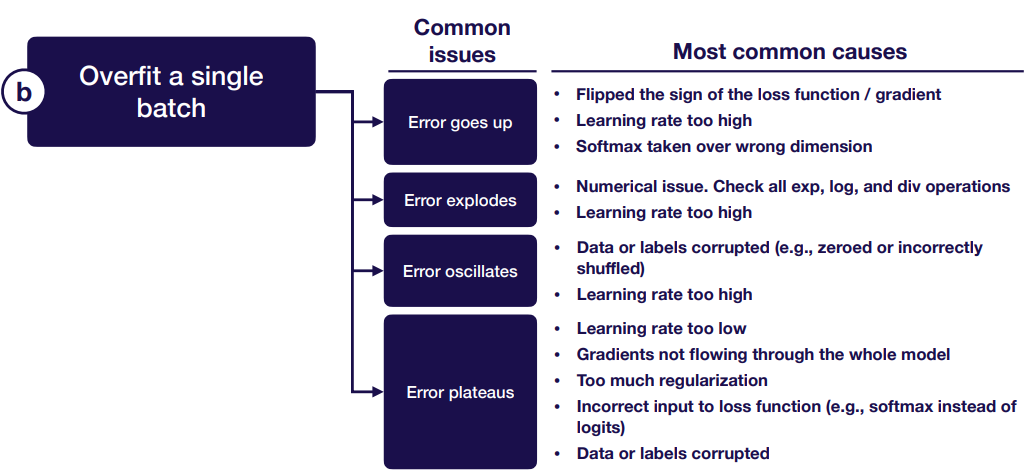
모델을 실행한 후 다음으로 해야 할 일은 단일 데이터 배치를 과대 적합시키는 것이다. 수많은 버그를 잡을 수 있게 하기 위해서 임의로 당신의 train error를 0에 가깝게 만들려고 하는 것이다.
다음으로 bug를 잡는 방법은 이미 알려져있는 것들과 우리의 것들을 비교해보는 것이다.
사용한 official code와 우리의 코드를 line by line 비교하는 것을 시작해서 모든 것들을 비교해보면서 출력 및 성능이 유사한지 확인을 한다.
우리가 사용하는 데이터에 대해서 정확한 체크를 할 수 없다면, 유사한 벤치마크 데이터 셋을 활용한 것들을 찾아보자.
이렇게 하나씩 얻으며 찾는 것은 실험의 오류를 줄일 수 있다.

- Evaluate
모델을 평가해서 다시 훈련을 시킬 때 우선순위를 정하기 위해서 bias - variance 분해를 적용한다.
* Test error = irreducible error + bias + variance + validation overfitting
Irreducible error : baseline error
Avoidable bias : train error와 irreducibel error의 차이
Variance : train error와 valid error 차이
Validation set overfitting: valid error와 test error의 차이
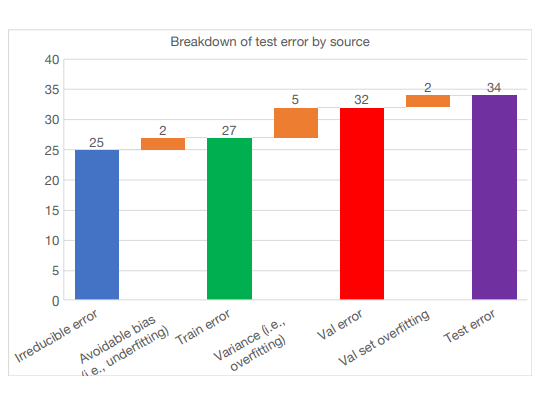
Test error에 bias-variance 분해를 적용하면 우선순위를 정하는데 도움이 되지만 이는 데이터가 모두 동일 분포에서 나온다는 가정이 있다. 그렇지 못 할 때는, distribution shift를 한다.
train과 valid or test distribution을 기반한 evaluation set을 구축하게 되면 distribution shift를 적용할 수 잇는데, 이를 validation error 와 test error의 차이로 산출할 수가 있다. 이를 이용해서 식을 업데이트하여 에러를 구할 수 있다.
* Test error = irreducible error + bias + variance + distribution shift + validation overfitting
- 모델 개선

Address under-fitting
언더피팅을 해결하는 방법으로는 , 모델을 확장하거나, 데이터에 정규화를 적용하는 방법등이 있는데, 적용할 방법의 우선순위로는 아래의 그림과 같다.

Address over-fitting
오버피팅 방지에는 데이터 수 늘리기, normalization 등이 있으며 early stopping, feature 제거, 모델 축소 등은 권장하지 않는다고 한다.

Address distribution shift

Rebalance datasets
test-valid set이 test set 성능보다 좋다면 valid set에 오버피팅 된 가능성도 있기 때문에, valid set을 재정의하여 새로 성능을 구해야한다.
검정 검증 집합 성능이 검정 성능보다 훨씬 좋아 보이기 시작하면 검증 집합을 과대 적합시킨 것일 수 있습니다. 이는 일반적으로 작은 검증 세트 또는 많은 하이퍼 파라미터 훈련에서 발생한다. 이러한 문제가 발생하면 검정 분포에서 검증 세트를 다시 표본으로 추출하여 성능을 새로 추정합니다.
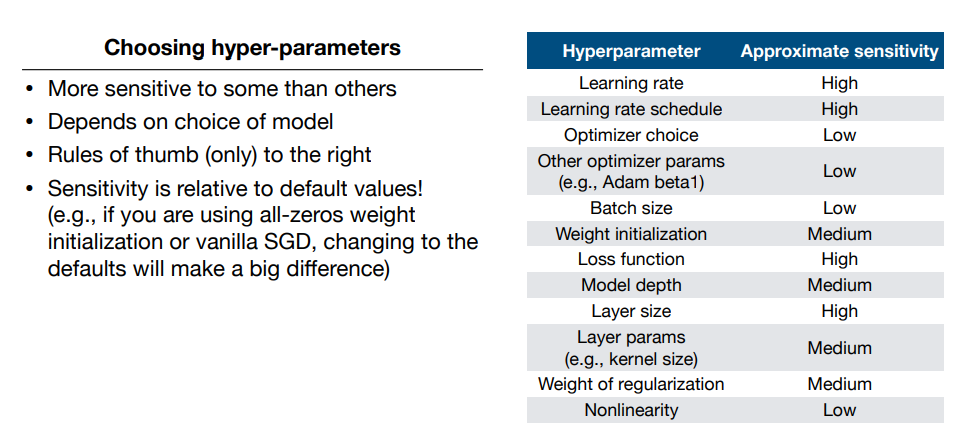
- 하이퍼 파라메터 튜닝
다양한 하이퍼 파라메터들을 수정하면서 최적의 성능을 구할 수 잇는데, 일반적으로 하이퍼파라메터들의 중요도는 아래의 표를 참고하면 도움이 될 것 같다.
파라메터를 찾는 방법 중 하나로 random search가 보통 효율적이라고 말하는데, N개의 point를 랜덤으로 선택해서 튜닝하는 방법으로 효율성인 부분에서는 그리드 서치보다 좋지만, 가끔 해석 불가능한 파라메터 조합으로 설명이 불가능 할 때가 있다.

다른 방법으로는 베이지안 추정을 통하여 파라메터 튜닝을 하는 것이다. 매개변수와 모델 성능 사이에 확률 모델을 유지하여, Expectation을 최대화 하는 파라메터 값을 사용해서 튜닝을 하는데, 매우 간편하고 효율적인 선택방법이라고 한다.

'MLOPS > full stack deep learning review' 카테고리의 다른 글
| Week11 Deployment & Monitoring part1 (0) | 2021.11.18 |
|---|---|
| Week 8. Data Management (0) | 2021.10.28 |
| week6. Infrastructure & Tooling (0) | 2021.10.11 |
| Self-Attention, Transformer (0) | 2021.09.29 |
| Week2. CNN (0) | 2021.09.25 |
