
rueki
딥러닝 Optimization 함수 정리 본문
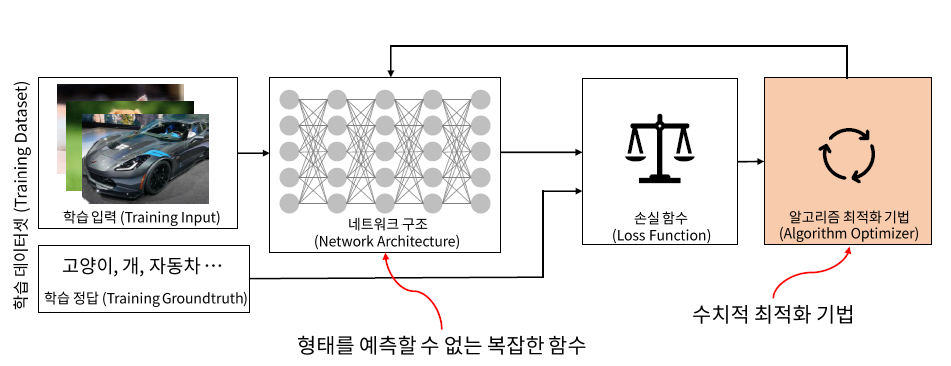
minimize f(x) -> 목적함수가 최소가 되는 x 값을 찾기!
딥러닝에서 최적화 알고리즘은 미분 사용
딥러닝에서 최적화 process 및 최적화 목적
: 학습을 통해 손실함수가 최소가 되게하는 파라메터를 구하자

-
Gradient Descent
-
DL/ML을 공부하면서 제일 처음으로 항상 등장하는 개념
머신러닝에서는 theta θ 를 갖는 목적함수 J(θ) 를 최소화 하는 것을 목표로 하고, 딥러닝에서는 loss function의 loss를 최소화로 하는 파라메터 θ를 찾는 것이 목표였다.


alpha는 알다시피 learning rate를 나타내며, 얼마나 update를 할 지에 대한 정도라고 볼 수 있다. lr이 작으면 수렴하는 속도가 감소하며, 반대로 큰 값을 가질 수록 minimum을 지나치거나 발산할 수가 있다.
1.1 Batch Gradient Descent
배치의 개념은 데이터 전체라는 의미를 가지고 있다.
즉, 배치 학습이라 함은, 전체 데이터에 대해서 학습을 하겠다는 의미이며, 위의 Gradient Descent도 Batch Gradient Descent이다. 즉, 데이터 N개를 모두 사용해서 loss function을 정의한다는 것이다.

위의 그래프처럼 loss function이 Convex 할 경우에는 global minimum이 보장이 되지만, 오른쪽과 같이 Non - convex 할 경우 Local minimum에 빠질 위험이 있다.
이제 SGD (stochastic gradient descent)를 소개할 텐데, 이는 Batch Gradient descent를 보완한 것이다.
2. SGD (stochastic gradient descent)
경사하강에 대한 계산을 할 경우 한번 step을 내딛을 때 전체 데이터에 대해 Loss Function을 계산해야 하므로 너무 많은 계산량이 필요하다. 그리고 계산 시간도 데이터가 클 수록 어마어마 할 것이다. 그래서 이를 미니배치로 적용해서 미니배치 크기 만큼의 데이터에 대해 손실을 계산하는 방법이다. 이는 배치 경사하강법보다는 덜 정확하다고 볼 수 있으나, 같은 시간에 학습을 더 많이 하기에 결과적으로는 크게 다르지 않다고 한다.
그러나 단점으로는 작은 데이터 단위마다 함수가 결정이 되니, 매 업데이트마다 일정한 크기의 기울기로 파라메터를 업데이트를 할 수가 없다.
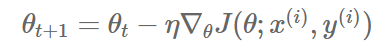

경사 하강법의 단점으로 위에서 1절에서 언급한 local minimum의 문제와 Saddle point(기울기는 0이나 극값이 아닌 지점) 이 있다. 이를 해결하고자 이제 Momentum의 개념이 등장한다.

3. Momentum

momentum의 사전적 정의는 관성이라는 의미를 가지고 있다. 간단하게 생각하면 local miminum에 빠진 point에 관성을 주어서 위의 그림과 같이 잘 굴러가게 하자는 것이 목적이다. 그러면 어떻게 잘 굴러가게 하는가? 이것에 대한 답은 이동 벡터를 사용하여 이전 기울기에 영향을 받도록 한다는 것이다.

γ(gamma) : Momentum 계수 - 보통 0.9로 사용
η (learning rate) : 학습율
Vt : t번째 step에서의 x의 이동벡터
식을 풀이하면 과거의 이동 벡터 Vt-1 를 기억하고 이데 대해 관성을 곱해준 후, 기울기를 이용한 이동 step 항을 더해준다.
Momentum의 개념을 사용해서 local minimum에 빠져나오는 효과가 있지만, 이동벡터에 대해 저장을 해야하기 때문에 메모리 사용이 배로 늘어난다는 단점이 있다.
4. NAG(Nesterov accelerated Gradient)

NAG의 개념은 모멘텀과 유사하다. 그러나 NAG만의 특징을 나타내자면, 관성을 줬을 때 원할한 속도로 잘 내려가면 이상적이지만, 갈수록 속도가 증가하여 왼쪽의 그래프처럼 크게 튀게 될 가능성이 있기에 이를 개선하고자 나온 것이 NAG이다. 즉, 정리하자면, 현재의 관성을 조절하여, 업데이트의 크기를 바꾸는 방식이다.
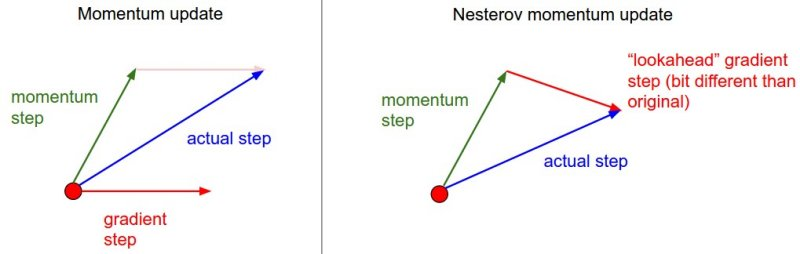
모멘텀에서 이동벡터를 계산할 때는, 현재 위치에서 기울기와 momentum step을 독립적으로 계산하고 합치지만,
NAG는 momentum step을 고려해서 현재의 기울기에 gradient step을 이동한다.

5 . Adagrad (Adaptive Gradient)
여기서부터는 위의 3가지 방식과는 다른 개념의 방법들이 소개가 될 것이다.
SGD부터 NAG의 문제점이라 함은, 모든 파라메터에 대해서 같은 learning rate를 적용시킨다는 점이다. 이것이 왜 문제가 되느냐? 예를들어 순전파 과정에서 다음 레이어에 전달하기 위해서 Wx (가중치 * 현재 레이어 입력)을 전달하게 되는데 이를 방정식으로 풀게 되면, 아래의 식이 될 것이다. 만약에 x2가 입력이 sparse 해서

0이 많이 존재하게 된다면, 그것에 대한 값은 없는 값이나 마찬가지가 되고, 가중치에 대해서 미분을 진행해도 값이 0이 나올 것이다. 이는 weight update가 되지 않는 다는 것을 설명할 수가 있다. 이후에는 x2가 0이 아닌 값을 가진다면, 이를 또 업데이트 하게 되는데 다른 파라메터 값들에 비해서 늦게 업데이트가 시작되어, 파라메터 간의 업데이트 격차를 줄여줄 필요가 있는데 여기서 이제 적응형 기울기라는 정의를 가진 Adagrad가 적용되게 된다.
Adagrad는 변수별로 학습율이 달라지게 조절하는 알고리즘이다.
기울기가 커서 학습이 많이 된 변수는 학습율을 감소시키고, 다른 변수들이 잘 학습되도록 한다.
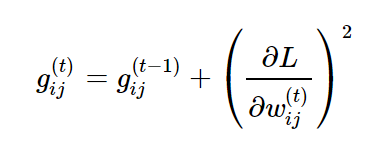
누적 기울기 크기를 계속 더해옴으로써, 현재 step에서 각 변수가 얼마나 변화했는지를 알 수가 있으며,

t번째 스텝까지 누적 기울기 크기를 나타내는 g를 learning rate에 남우에 따라 g값이 클 수록 learning rate가 작아지는 것을 알 수가 있다.
각각의 파라메터보다 적절한 learning rate를 적용시킨다는 장점이 adagrad의 장점이지만, 학습 횟수가 점점 많아질 수록, g값이 커지기 때문에, learning rate는 계속 작아질 수 밖에 없고 가중치 업데이트가 안된다. 이를 보완한 것이 rmsprop과 adadelta이다.
6. Rmsprop( Root Mean Square Propagation)
학습이 진행될 수록 lr이 감소되는 adagrad의 문제점을 해결해주는 방법인데, adagrad에서는 g를 기울기 제곱 합으로 나타냈으나 여기서는 제곱의 지수 이동 평균으로 나타냈다. 이로써 g가 무한정 커지지 않고, 최근 변화량의 변수 간 상대적인 크기 차이를 유지할 수가 있다고 한다.


가중치를 update하는 식은 adagrad와 같으나 g의 식에서 B값이 등장한 것을 볼 수가 있다. 베타값은 지수평균 업데이트 계수를 나타내며, B값으로 인해 g가 계속 증가하는 일이 없어서 학습을 오래할 수 있게 된다.
7. Adam (Adaptive Moment Estimation)
Adam 은 RMSprop과 Momentum 방식을 합친 것으로 알려져있는 알고리즘이며 대부분의 딥러닝 최적화에 많이 쓰이는 것을 볼 수가 있다.
현재까지 계산해온 기울기의 지수평균을 저장하고, 기울기의 제곱값의 지수 평균을 저장하는 방식을 사용한다.

가중치의 momentum인 v와 lr을 조절하는 g에 대해 지수평균 이동으로 계산을 하는데 위의 식은 rmsprop에서 본 식과 유사한 식임을 알 수가 있다.
B1과 B2 는 각각 0.9와 0.999를 default로 하는 편이다.
위의 값들을 초기값으로 0으로 주면 학습 초기에 weight가 0으로 편향되는 경향이 있기에 편향을 잡아주기 위해 위와 같은 계싼을 적용하고 최종적으로 weight update는 아래와 같이 진행하게 된다.


'DL' 카테고리의 다른 글
| Generative Adversarial Nets (GAN) 논문, 코드 리뷰 (0) | 2020.12.03 |
|---|---|
| Attention과 Transformer 까지 정리 (0) | 2020.09.10 |
| Batch Normalization (0) | 2020.07.05 |
| Adam Optimizer (adaptive moment estimation) (0) | 2020.07.05 |
| RNN과 LSTM에 대해서 알아보자 (0) | 2020.04.04 |



