
rueki
Adam Optimizer (adaptive moment estimation) 본문
지금 성능 좋기로 제일 많이 나와있고, 많이 쓰이는 Adam optimizer 알고리즘에 대해서 알아보려고한다.
Momentum과 RMSprop을 합친 알고리즘으로서, 다양한 범위의 딥러닝 구조에서 잘 작동한다고 소개되있기도 한다.
알고리즘을 살펴보기 전에, 파라메터의 종류에 대해 먼저 살펴보고자 한다.
a (learning rate) : 어느 최적화 알고리즘에서나 나오듯, 이 부분이 보편적으로 많이 보이면서 중요하다.
완벽한 최적의 값을 알 수 없기에, 찾을 때까지 학습을 하며 바꾼다.
$B_{1}$ : 모멘텀 부분에 관련된 파라메터로서 이동 평균 및 가중 평균을 의미하고 default로 0.9정도로 사용하면
좋다고 한다.
$B_{2}$ : 이동가중평균이다. 0.999가 좋다고 한다.
ϵ : 값의 변화에 큰 역활을 하지는 않지만 추천하는 값으로는 10의 -8승정도라고 한다.
논문에서 소개된 Adam의 장점은 stepsize가 Gradient의 rescaling에 영향을 받지 않는다는 것인데,
이는 안정적으로 최적화를 할 수 있다는 뜻이다.

여기서 v(momentum 1차벡터)와 h(momentum 2차벡터)는 각각 처음에 0으로 설정해서, 학습 초반에
0으로 biased되는 문제를 해결한다.

이 부분에서 설명하고자 하는 것은, 모멘텀과 유사하게 기울기의 지수 평균을 저장하고, RMSprop과 유사하게 기울기의 제곱값을 지수 평균을 저장하는 것이다.
이제 이 값들을 가지고 기울기 update를 하면 수도 코드에서의 맨 마지막 내용을 설명할 수가 있다.
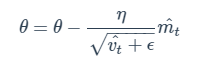
기울기가 곱해질 자리에 m을 넣고, 분모자리에 Gt 대신에 v를 넣어 계산을 진행한다.
'DL' 카테고리의 다른 글
| 딥러닝 Optimization 함수 정리 (0) | 2020.08.26 |
|---|---|
| Batch Normalization (0) | 2020.07.05 |
| RNN과 LSTM에 대해서 알아보자 (0) | 2020.04.04 |
| 2. Activation Function (0) | 2020.02.18 |
| 1. Forward Propagation (0) | 2020.02.18 |



