
rueki
Course1_Week 2. Select and Train a Model 본문
2주차 내용은 Select and Train a Model에 관한 내용이다.
내용을 요약하자면 전반적으로 모델 훈련을 어떤 측면에서 고려하며 진행을 하고 관리하는 프로세스에 대해서 배운다.
Ai 시스템과 다른 소프트웨어 시스템과의 차이라함은 데이터의 존재 유무이다. code로만 실행하고, 다루는 것을 일반적인 소프트웨어 시스템이라 하면, Ai 시스템은 Code + data로 볼 수가 있다. 다만 data에 대해서는 flexibility를 강조했는데, 이 의미는 특정 데이터에 대해서만 모델이 잘 동작하는 것보다 보다 범용적으로 잘 되어야 AI system으로 나아갈 수 있다는 점인 것 같다.
머신러닝 모델은 Model, Data, Hyper parameters 이렇게 3개로 구성되어 있다고 볼 수가 있는데,
모델을 function이라고 볼 때, input x -> f(x) -> output y 단면적으로 이렇게 구성되어 있다. hyp는 모델을 구성하는 세부적인 요소인데, 결국에 모델을 개선한다라고 함은 이 3가지 부분을 중점적으로 봐야한다.

모델을 개선할 때 중요 사항으로 봐야할 것들은 아래와 같다.
- Train error
- valid / test set 에 잘 동작하는지
- Metrics, project goals
모델 학습에 처음으로 우리가 직면할 수 있는 부분은 훈련 셋에 대한 에러이다. 이것을 기준으로 훈련이 잘 진행되는지 안 되는지 우선적으로 판단할 수가 있다.
그리고 모델이 잘 훈련된 것 같다고 판단한 후, 검증 및 테스트 셋에 적용을 해보는데 이 역시 잘 된다면 좋은 모델이라고 충분히 얘기할 수가 있다.
마지막으로 수치적 성능이 어느정도 나오는지, 우리가 훈련한 모델이 정의한 프로젝트에 적합한지 고려를 했을 때 적합하다 생각이 되면 이것을 하나의 product로 배포할 수 있을 것이다.
그러나 여기서 짚고 가야할 부분이 한 가지가 있다. train error도 낮고, test error도 낮으면 잘 된 것 아닌가라고 생각할 수 있으나, 이것은 1차적인 부분에서 합격인 것이고, 실제환경에서는 오히려 안 좋게 성능을 내보일 수 있다는 것을 알아두자.
우리가 그럼 ML project를 만든다 할 때 성능 척도의 기준을 무엇으로 잡아야할지 선정을 해야한다. 즉 이것을 baseline을 정한다라고 얘기할 수 있는데, 다른 모델 및 기존의 sota를 정하기 이전에 고려해볼 것은 HLP(Human level performance), 사람이 판단했을 때 어느정도 비교가 될까라는 것이다.
예를 들어 개와 고양이를 분류한다고 할 때, 사람은 높은 가능성으로 개와 고양이를 구분할 수 있는데, 학습시킨 모델이 100%는 아닐지라도 사람보다는 좋은 성능을 보여야 인공지능 시스템이라고 얘기를 할 수 있지 않을까?
그 다음으로 baseline으로 적합한 것은 앞에서 얘기한 Sota model과 이전에 좋은 성능을 보였었던 오래된 모델정도를 정할 수 있을 것이다.
ML Project 요약
오픈 소스를 활용해서 실생활에 적용할 시스템을 만드는 것
정의한 프로젝트 목표에 따른 데이터 선정 및 전처리에 대해 신뢰도가 높아야함
baseline 정하기
Error analysis
머신러닝 모델의 예측값이 ground truth와 차이가 거의 없다면 이것은 최상의 모델이지만, 이런 경우는 아직까지는 드물다. 그러면 gt와 predicted value가 차이나는 이유를 보자면, data가 최고의 quality가 아닌 이유가 대다수인 것 같다.
data에 noise가 껴있는 경우가 많은데 그 예시로 음성데이터에 완전히 깔끔한 음성만 존재하지 않고 보통은 뒷배경소리와 같은 소음이 껴있다. 결국에는 양질의 데이터는 적게 존재할 수 밖에 없다.
그래서 이를 해결하고자 데이터를 추가로 수집하는 것도 하나의 좋은 방법이지만, 데이터 augmentation도 인기있는 하나의 방법으로 많이들 사용하고는 있다.
다른 관점에서 또 바라볼 수가 있는데 대부분의 dataset들이 편향되어 있다. 이 뜻은 즉 이진분류를 가정했을 때, 정상과 비정상의 비율이 50대 50을 유지하는 경우는 극히 드물고, 보통은 99 : 1일정도로 한 쪽의 데이터가 많이 부족하다.

위의 task는 비정상 데이터를 가리는 것인데, precision과 recall의 차이가 9퍼센트 정도 차이가 난다. 이것이 그렇게 좋은 값은 아니지만 그래도 어느정도는 감안할 수 있다고 본다. 그러나 precision이 97, recall이 7.3인 경우에 F1-score를 구하면 13.6밖에 나오지 않는다. 위의 경우에는 83프로나 나오는데 말이다. 결국 데이터가 편향될 경우 Metrics적인 측면에서 기대하지도 못한 결과를 야기할 수 있어서 이 역시 고려해야할 사항 중 하나이다.
앞서서는 학습 및 데이터의 측면에서 error 분석을 다뤘다면, 이번에는 성능 부분을 다룬다.
Metric이 결국에 모델의 성능을 얘기하는 수치적인 부분인데, 우리에게 드러나는 수치적 성능이 좋아도 여러가지를 고려해볼 필요가 있다.
- Data subset에서의 성능
- 같은 error가 얼마나 발생하는지
- rare classes에서의 성능
위의 3가지는 일부 데이터 (ex . data를 slicing 한 subset)에서 확인을 해볼수가 있다.
Data iteration
모델 성능 개발에서 두 가지 관점으로 분류를 할 수가 있는데, Data-centric, Model-centric으로 볼 수 있다.
- Model centric
: 가지고 있는 data에 한해서 모델 성능을 개발한다. -> 일반적으로 Academic한 특성으로 진행되는 것(Research)
쉽게 얘기하면, 보통 논문에서 open dataset을 가지고 모델 개발 및 성능 향상에 대한 부분을 내는데, 이런 부분으로 생각하면 될 것 같다.
- Data centric
: 모델 성능을 높이는 데 가장 단순하면서 어려운 방법은 데이터를 늘리거나 data의 quality를 높이는 것이다. 그러나 이것이 실질적으로 쉽지는 않기에 data augmentation이라는 방법을 쓰기도 한다.
요약하자면, 모델에 관한 code는 최대한 fix하고, data를 계속 발전시키는 방향으로 가는 것이다.
현실적으로 Data augmentation이 적용하기 제일 좋은 방법 같은데, 이것에 다루기 앞서 데이터는 대부분 멀티 클래스로 존재할텐데 어떤 부분에 augmentation을 적용해야할까?
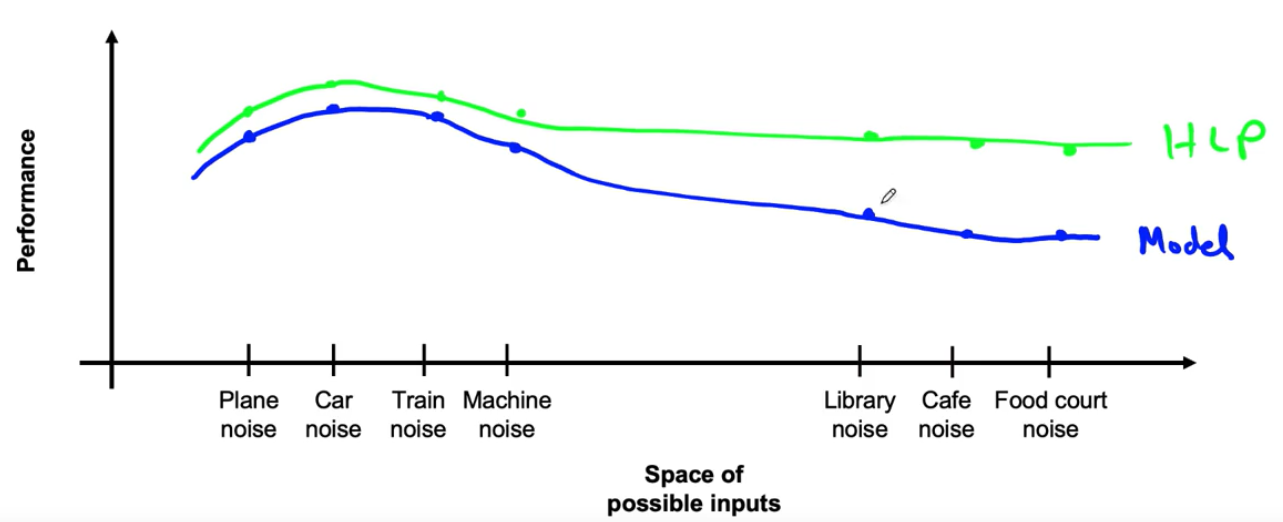
위의 그래프에서 보면 왼쪽 데이터에서는 Human level performance와 Model performance가 어느정도 비슷한데, 오른쪽 부분은 그렇지 못 하다. 그렇다면 오른쪽 특성을 가지고있는 데이터에 대해서 더 많은 데이터를 가지고 있다면 성능을 높일 수 있지않을까 라고 생각 할 수 있을 것 같다.
Data augementation이 그럼 무엇인지 알아볼텐데 간략하게 보면 기존의 데이터를 이용해 새로운 데이터로 보이게끔 하여 데이터 양을 늘리는 것인데 예시로 이미지에 약간의 noise를 추가하게 되면 원본 이미지와는 또 다른 데이터로 볼 수 있을 것이다.
그렇다고 무작정 늘릴 수는 없으니, augmentation한 data도 realistic 한지, HLP에서도 충분히 좋은 성능을 내보이는지, 모델 알고리즘의 성능 변화정도가 있는지 고려해야 할 것이다.
범용적으로는 data augmentation하는 것이 좋다지만, 안 좋은 경우도 존재한다.
가지고 있는 데이터만으로도 모델 성능이 충분히 잘 나오거나, 모델이 너무 커서 low bias인 경우에는 데이터를 늘려도 오히려 성능이 감소될 수가 있다.
'MLOPS > Coursera_mlops' 카테고리의 다른 글
| Course1_Week3. Data Definition and Baseline (0) | 2021.11.21 |
|---|