
rueki
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network (SR-GAN) 본문
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network (SR-GAN)
륵기 2021. 2. 28. 14:371. Abstract
Deep Convolution Network로 Single Image Super-Resolution 분야에서 정확도와 속도적인 측면에서는 해결이 되었으나 큰 계수로 upscaling 할 때의 미세한 texture detail들은 어떻게 복원할지가 여전히 문제라고 한다.
이전까지의 연구에서는 MSRE(Mean Squared reconstruction error)를 최소화시기는데에 목적을 두고 있었다. 그러나 결과값에서 고주파 세부정보가 부족하고, 고해상도에서 기대한 fidelity(충실도)와 맞지 않는다는 점에서 문제로 보여지고 있었다.
본문에서 Gan을 이용한 Super Resolution, 즉 SR-GAN을 소개하는데, 4배 이상 upscaling factor에 대해 natural image를 유추하는 것이 첫 번째 프레임워크로써 이를 위해서 adversarial loss와 content loss로 구성된 loss 함수를 제안한다.
Adversarial loss는 고해상도 사진과 원본 이미지를 구별하는 역할을 하는 discriminator를 사용해서 본문서 제안하는 solution을 natural image manifold로 들어간다고 한다. 그리고 Content loss에서는 pixel space의 유사성 대신에 perceptual similarity를 토대로 사용한다고 한다. Residual network로 downsampling 된 이미지를 복원할 수 있다.
그리고 SRGAN의 성능은 Mean-Opinion-Score(MOS)로 나타낸다고 한다.
2. Introduction
Low Resolution에서 High Resolution으로 이미지를 추정하는 것은 매우 어려운 작업인데 이를 Super Resolution이라고 한다.

위의 사진은 abstract에서 소개한 4 x Upscaling한 사진과 원본과의 비교를 나타낸다.
Super Resolution에 대한 잘못된 정보가 재구성된 SR 영상의 텍스처 디테일이 일반적으로 없는 높은 스케일링 인자에 대해 두드러진다는 것인데, 여기서 optimization target은 복원된 High resolution 이미지와 실제 이미지 간의 MSE를 최소화 시기는 것이다. MSE를 최소화 시키면, Super Resolution 알고리즘을 평가하는데 사용되는 PSNR(최대 신호 대 잡음비)가 최대화 되기에 매우 편리하다고 한다. 그러나 이의 단점은 perceptual한 차이를 잡아내려고 할 때, 픽셀 간의 차이로는 한계점이 있다고 한다.

위의 결과에서 보면 PSNR이 가장 높은 2번째 사진과 SRGAN의 결과인 3번째 사진을 보면 수치적으로만 두 사진중 뭐가 낫냐고 판별하기가 정확하지 않다는 점이다.
본 논문에서는 이제 SR-Gan에 대해 소개를 하는데, ResNet 기반 네트워크를 사용하는데 기존의 다른 네트워크와의 차이라면 VGG를 이용해서 high level feature map을 추출하여 perceptual losss를 정의한다는 것이다.
2.1 Related Work
- Image Super resolution
SISR(Single image super resolution)만 다룰 것인데, Prediction-based methods는 SISR에 문제가 되는 기벙으로써, 매우 빠르다는 장점이 있는 반면에, 지나치게 부드러운 texture를 산출한다는 문제가 있다. 그리고 많은 기법들이 example-pari에 의존한 LR training을 기본으로 생각하고 있다.
그리고 SR의 문제에 대한 접근 방식은 compressed sensing에 비롯되기에, 이미지 내의 전체적인 scale에 걸쳐 patch redundance를 활용해서 Super Resolution을 행한다고 한다. 그 외에도 다른 연구서는 전체 이미지를 처리하여 일관성을 개선하는 Convolution Sparse coding 기법을 제안했다.
그리고 Neighborhood Embedding 기법은 저차원 매니폴드에서 유사 LR Patch들을 찾아 HR Patch들과 결합하여 LR 이미지 패치를 샘플링한다고 한다. 그 외에도 많은 기법들이 있었으나, CNN을 통해서 성능이 좋은 이후로 CNN이 자리를 잡았다.
- Design of convolutional neural networks
CNN구조 깊어질 수록 훈련하기 힘들지만, 네트워크의 정확도는 올라갈 수도 있다는 특징을 가지고 있다.
네트웤 구조를 효과적으로 학습하기 위해서는 배치 정규화를 사용하고는 하는데, Deep CNN은 SISR에서도 성능을 향상시킨다는 것을 보여주었으며, Skip Connection을 통해서 더 효과를 볼 수 있었다.
- Loss Function
Pixel 단위의 MSE 기반 loss function을 사용하면 손실된 high frequency 정보 복구에 있어서 불확실할 수 있다.
그러나 MSE를 minimize하게 되면, 지나치게 smooth하게 되면서, 안 좋은 perceptual quality를 가지는 pixel-wise 평균값을 찾을 수 있게 된다.

Figure 3은 MSE를 최소화 할 때의 문제를 나타낸 것인데, 실제 이미지와 비교를 해보면 MSE Solution의 이미지가 지나치게 smooth하다는 것을 볼 수가 있다. 그래서 이 문제를 해결하고자 이미지 생성모델에 사용되는 GAN을 도입하기로 했다고 한다.
2.2 Contribution
Image Super Resolution을 위해 사용되는 구조로 16개의 블록을 가진 ResNet을 사용하며, PSNR과 SSIM(Structural Similarity)로 성능 측정을 하며 MSE로 optimizing을 한다. 그리고 SRGAN은 Gan을 기반으로한 네트워크로서 새로운 loss를 제안한다.
3. Method

Single Image Super Resolution의 목표는 low resolution image 에서 high resolution을 하는 것이다.
훈련시, 고해상도의 이미지에 가우시안 필터를 적용시키면 값이 전체적으로 정규 분포의 값을 가지게 되면서, smooth하게 된다. 여기서 downsampling 계수 r을 사용하게 되는데 low resolution image가 W x H x C의 구조를 가진다고 하면, High resolution image는 rW x rH x C의 구조를 가지게 된다.
논문서 제안하는 모델의 최종 목표는 저해상도 입력 이미지에 대해 고해상도 이미지를 추정하게끔, Generator fuction G를 train 하는 것이다. 이를 위해서는 CNN에서 Generator parameter인 $G_{\theta g}$ 를 훈련시겨야 한다.

loss의 weighted combination으로 perceptual loss인 Super resolved loss를 설계한다고 한다.
3.1 Adversarial Network architecture


첫 번째 함수는 14년도 이안 굿펠로우가 소개한 GAN의 loss function이며 두 번째 함수는 SR-GAN에서의 function이다.
둘의 차이를 보면 수식 자체에는 큰 변화가 없고 입력값에 대한 것만 다르다는 것을 알 수가 있다.
이 함수의 idea는 고해상도 이미지와 실제 이미지를 구별하는 역할을 할 discriminator를 속일 목적으로 Generative model를 훈련시키는 것이다.

3.2 Perceptual Loss Function

SR-GAN의 중점이 되는 Perceptual loss는 content loss와 Adversarial loss로 구성이 되어 있다. 이는 모드 Mean Squared Error function을 기반으로 설계되었다고 한다.
3.2.1 Content Loss

Image resolution에 널리 사용된 optimization 기법인데, 높은 PSNR 값을 얻기위해 MSE를 optimizing하는 데 있어서,
지나치게 smooth한 texture를 가지게 됨에 따라 불만족스러운 결과가 나오는, 즉 고주파 성분이 부족하게 되는 결과를 가져오게 된다고 한다. 그래서 Pixel-wise 기반 loss 대신에, perceptual similarity 기반의 loss를 사용했다.
그래서 VGG Loss라는 것이 나오는데 pretrain 된 VGG19 network를 이용해서 정의를 한다고 한다. 그래서 생성이미지 (reconstructed image)와 원래의 고해상도 이미지와의 비교를 Euclidean distance로 정의를 한다.

여기서 W와 H값은 vgg network에서 나온 feature map의 차원을 의미한다고 한다.
ϕ 값이 feature map value를 나타내며 i는 Max-pooling layer index, j는 몇번째 conv layer인지 나타내는 index value이다.
3.2.2 Adversarial loss
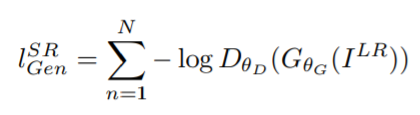
Generator의 목적은 결국 Discriminator가 판별을 잘하지 못 하게끔, 완벽하게 fake 결과물을 만드는 것에 있다.
여기서는 기울기를 더 낫게 minimize하기 위해서 Negative log를 사용한다고 한다.
4. Experiments
4.1 Data and Similarity measures
모든 실험은 Scale factor 4x 로 설정을 했고, train은 Set5, Set14, BSD100에서 했고, 테스트는 BSD300에서 진행을 했다고 한다. 성능 비교 척도는 PSNR과 SSIM을 사용했다.
4.2 Training details and parameters
Train 시에 ImageNet 데이터에서 3백 50만 장의 임의 데이터를 사용하고 테스트 데이터는 별개의 데이터를 사용했다고 한다. 그리고 고해상도에서 저해상도로 downSampling한 이미지를 포함(downsampling factor : 4)하였고, 매 배치마다 별개로 96 x 96 사이즈의 sub image를 포함했다. input Image의 값 범위는 0 ~ 1로, High resolution Image는 -1 ~ 1로 스케일을 설정했다. 그리고 VGG feature map은 계수값 1/12.75 를 사용하며 MSE Loss에 필적하는 VGG Loss를 보였다.

SRResNet 네트웍에서는 learning rate로 10^-4의 값을 사용하였고, optimization에는 Adam optimizer를 사용했다.
그리고 Residual block 16를 생성 모델에 사용했으며, 테스트 할 동안, 배치 정규화를 하지 않으며, 입력에만 의존하는 출력을 얻게 되었다고 한다.
4.3 Mean opinion Score (MOS) testing


각각의 Network에 대해서 MOS test를 하여 SCORE를 산정한 결과물이다.
-> Mean opinion Score
MOS를 직역하자면 '평균의견점수'라고 부를 수 있을 것이다. 모집된 여러 명의 피실험자들이 점수를 매긴 것을 평균낸 것이 바로 MOS다. 예를 들어 10명의 피실험자들이 어떤 왜곡된 이미지를 보고 각각 95, 89, 82, 93, 90, 81, 88, 95, 92, 91과 같이 점수를 매겼다면 그 왜곡된 이미지의 MOS는 이 점수들의 평균인 89.6이 된다.
따라서 j번째 왜곡 이미지에 대한 MOS는 다음과 같은 식으로 나타낼 수 있다. N명의 피실험자가 참가했고, i번째 피실험자가 j번째 왜곡 이미지에 대해 매긴 점수를 S라고 아래의 수식이 나온다.

- 설명 : bskyvision.com/508
4.4 Investigation of Content Loss
Gan 기반 Network에서 사용하는 perceptual loss에서 다른 content loss를 investigate 한다.
그리고 SRResNet-MSE, SRResNet-VGG loss 두 가지로 generator performance를 평가한다.
앞에서 언급했듯이, MSE를 사용했을 때, 훨씬 smooth한 결과를 내비치며, 이로인해, Adversarial loss와 MSE Loss 간의 경쟁이 이루어지게 된다.
4.5 Performance of the final Networks
본문에서는 결국 SRResNet과 SR-GAN, Nearest Neighbor, bicubic interpolation 총 4개가 비교가 되는데,

표를 보면, SRResNet의 성능이 두드러지는 것을 볼 수가 있다.

5. Conclusion
SRResNet을 통해서 PSNR 성능 척도를 많이 향상시킬 수 있었다는 것을 확인할 수 있었으며, Image Resolution에서의 PSNR 한계를 GAN을 통해서 해결할 수 있었다고 한다.
'Gan' 카테고리의 다른 글
| ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks (0) | 2021.03.03 |
|---|---|
| Cycle Gan 정리 (0) | 2021.02.15 |

