
rueki
언어 모델 - 통계적 언어 모델(Statistical Language Model, SLM) 본문
앞의 글에서 언급했듯이 조건부 확률은 다음 언어의 예측에 있어서 중요하다.
p(B|A)=P(A,B)/P(A)
P(A,B)=P(A)P(B|A)
P(A,B,C,D)=P(A)P(B|A)P(C|A,B)P(D|A,B,C) -> 연쇄 법칙
=> P(x1,x2,x3...xn)=P(x1)P(x2|x1)P(x3|x1,x2)...P(xn|x1...xn−1)
쉽게 말하자면 x1과 x2가 있는데 그 다음 단어 x3의 확률을 알려면
x1과 x2가 조건으로 일어났을 때 x3의 조건부 확률을 구하면 되는 것이다.

전체 문장의 확률은 각 단어들이 이전 단어가 주어졌을 때 다음 단어로 등장할 확률의 곱으로 구성된다.
An adorable little boy is spreading smiles 라는 문장이 있을 때,
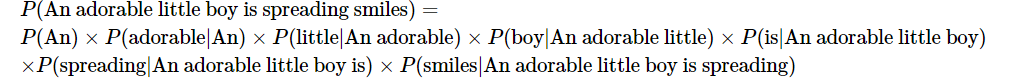
쉽게 말해서, 전체 문장의 확률을 계산하기 위해서는 각 단어에 대한 예측 확률들을 곱한다는 뜻이다.
확률 기반으로 통계적 언어 모델의 구성에 대해 알아보았다.
그렇다면 실제로는 다음 당너에 대한 확률은 어떻게 계산할까?
답은 카운트 기반으로 확률을 계산한다.
An adorable little boy가 나왔을 때, is가 나올 확률인 P(is|An adorable little boy)는 어떻게 구할까?
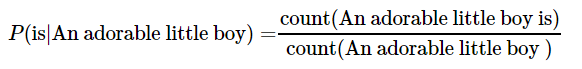
예를 들어 An adorable little boy 가 100번 등장하고, 그 뒤에 is가 30번 등장했다고 가정하면
확률은 30%라고 값이 나온다.
그런데 카운트 기반으로 접근하고자하면, 이에 대한 데이터 양은 어마마하게 많아야한다.
코퍼스에 해당 데이터가 없다면, 분모는 0이되서 결과값은 결국 0이 되어버린다.
이를 완하하는 방법은 n-gram 모델과 SLM의 일반화 등이 있다.
'DL > NLP' 카테고리의 다른 글
| 언어 모델 - 한국어 (0) | 2019.07.02 |
|---|---|
| 언어 모델 - N-gram Language Model (0) | 2019.07.02 |
| 언어 모델(Language Model) (0) | 2019.07.02 |
| 텍스트 전처리 - 원-핫 인코딩(One-hot encoding) (0) | 2019.07.02 |
| 텍스트 전처리 - 정수 인코딩(Integer Encoding) (0) | 2019.07.01 |

