
rueki
Distilling the Knowledge in a Neural Network 리뷰 본문
ML, DL에서 가장 좋은 성능을 보일 수 있는 간단한 방법은 큰 모델을 학습시키는 것이다. 그러나 실제 환경에서 큰 모델을 사용하는 것은 자원의 한계가 있는 부분이 많기 때문에 사실상 어렵다. 그래서 나온 방법이 학습된 큰 모델을 작은 모델로 안의 내용을 전달, 즉 지식을 전달하는 프로세스를 적용한 Knowledge Distilation 기법이 나왔다. 이를 통해서 누릴 수 있는 효과는, 모델의 사이즈는 작은 것을 사용하지만 성능은 큰 모델과 최대한 유사한 성능을 낼 수 있다는 점이다.
큰 모델의 일반화된 부분을 작은 모델로 이전하는 방법은 큰 모델의 아웃풋을 작은 모델의 target 값으로 사용하는 것인데 이를 soft target이라고 한다. 여기서 전이시킬 때 큰 모델 학습시킬 때와 같은 데이터를 써도 되고 분리시켜서 전이 전용 셋으로 써도 된다고 한다. 아래사진이 hard target과 soft target의 정의에 대한 차이를 잘 보여주는 것 같다.

여기서 Knowledge가 나타내는 것이 결국 무엇인가라는 궁금증이 생기는데, 모델 간에서 적용되는 개념은 입력을 통해 나온 softmax 결과값으로 이해하면 된다.
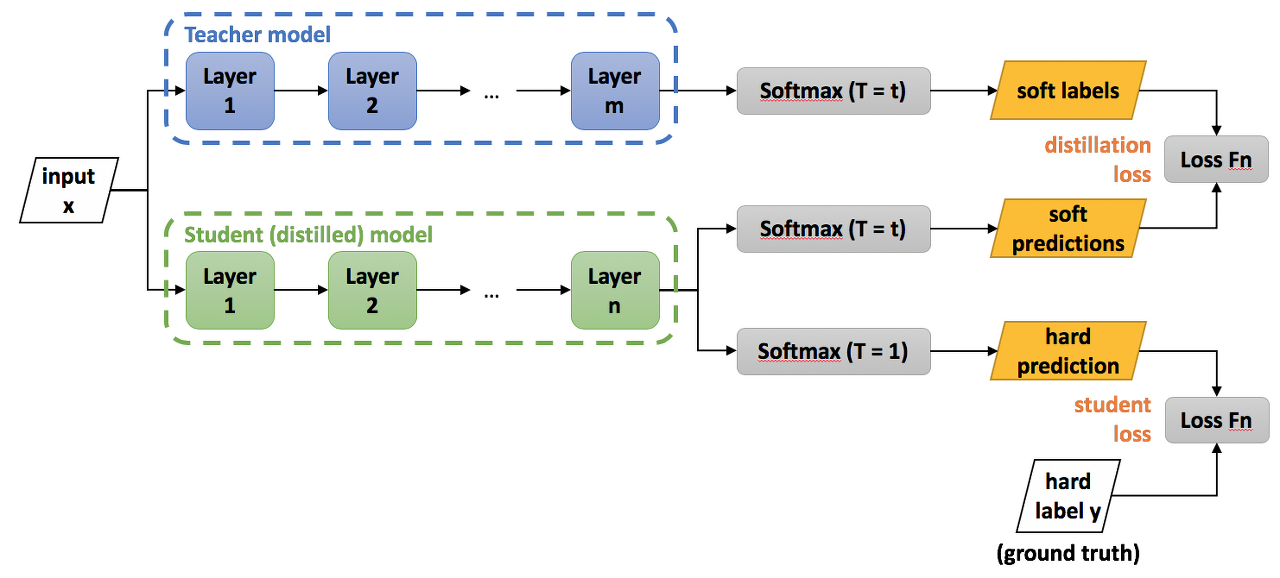
Distillation에서 사용되는 Softmax는 기존에 알던 Softmax 함수와 조금의 차이가 있다.

분모로 사용되는 T 값은 temperature라고 명칭이 되어 있는데 이 값에 따라 soft, hard의 정도가 달라진다. T가 높아지게 될 수록 Soft 해진다.
Knowledge Distillation의 학습 프로세스는 정리하면 아래와 같이 설명할 수가 있다.
- 큰 모델 학습(Teacher)
- Student 모델 학습 시 Teacher의 output과 label(ground truth)와 student model의 output 간의 loss를 이용
- Student 모델 학습 시에는 Teacher 모델은 evaluation 용으로만 사용하게 됨
- 위의 로스를 이용해서 student 모델이 학습하게 됨

Distillation Loss

'paper review' 카테고리의 다른 글
| [리뷰]Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers (0) | 2022.08.02 |
|---|---|
| WGAN 과 WGAN-GP (0) | 2021.07.24 |
| SinGAN: Learning a Generative Model from a Single Natural Image 리뷰 (0) | 2021.07.24 |
| Vision Transformer (AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE) 리뷰하기 (0) | 2021.07.20 |
| Self Attention Generative Adversarial Networks (0) | 2021.03.22 |


