
rueki
SQL 계층형 질의문, SELECT 문의 서브쿼리 본문
-
계층형 질의문
: 순위와 서열을 출력하는 SQL문
계층형 쿼리절은 where 절 다음에 기술하며, from 절이 수행된 후 수행된다.
Start with 절과 connect by 절로 구성
Start with 절이 수행된 후 connect by 절 수행
Start with 절은 생략이 가능하다.
Ex) select level, empno, ename, mgr
from emp
connect by prior empno = mgr;
select level, empno, ename, mgr
from emp
connect by prior empno = mgr;@ level은 조직도 서열을 나타낸다.

Ex) select level, empno, ename, mgr from emp
start with ename = 'KING'
connect by prior empno = mgr;
select level, empno, ename, mgr
from emp
start with ename = 'KING' connect by prior empno = mgr;
Ex) select rpad(' ', level*2) || ename as employee, sal
from emp
start with ename = 'KING'
connect by prior empno = mgr;
select rpad(' ', level*2) || ename as employee, sal
from emp
start with ename = 'KING'
connect by prior empno = mgr;

Siblings -> order by 계층 질의문 옵션
계층형 질의문에서 order by 절 사용시 siblings 옵션은 짝꿍과 같다
-
계층형 질의문과 sys_connect_by_path 함수
: sys_connect_by_path 함수를 이용하면 결과를 가로로 출력할 수가 있다.
Ex) select ename, sys_connect_by_path(ename,'/') as path
from emp
start with ename = 'KING'
connect by prior empno = mgr;

-
Select 문의 6가지절에서의 서브쿼리
Select -----------> 서브 쿼리 가능 // scalar 서브쿼리
From ------------> 서브 쿼리 가능 // inline view
Where -----------> 서브쿼리 가능 // subquery
Group by --------> 서브쿼리 불가능
Having -----------> 서브쿼리 가능 // subquery
Order by ---------> 서브쿼리 가능 // scalar subquery
-
Select 절의 서브쿼리 (scalar subquery)
Ex) 이름, 월급, 사원 테이블의 최대월급
select ename, sal, (select max(sal) from emp) 최대월급
from emp;
스칼라 서브쿼리 특징 - 단 하나의 값만 리턴할 수가 있다.
-
Having 절의 서브쿼리
-> Having 절 역시 where절과 유사하게 사용하면 된다.
직업, 직업별 토탈 월급 출력, 직업이 salesman의 토탈 월급 보다 더 큰 것만 출력하세요
-> select job, sum(sal)
from emp
group by deptno
having sum(sal) > (select sum(sal) from emp where job = 'SALESMAN');

-
상호관련 서브쿼리
: 메인쿼리의 컬럼이 서브쿼리 안에서 수행되는 sql
@ select 절 상호관련
Ex) 이름, 월급, 부서번호, 자기 부서번호의 토탈월급 출력
Select ename, sal, deptno, (select sum(sal) from emp s
where s.deptno = m.deptno) 토탈월급
from emp m;
서브쿼리 캐싱 --> select 절 서브쿼리에서 한번 수행한 결과를
메모리에 올려놓는다
그 다움부터는 메모리 올려놓은 데이터를 가져온다.
문제 283. BLAKE를 제외하고 emp 테이블의 계층을 나타내서 출력하세요
-> select rpad(' ',level*2) || ename as employee, sal
from emp
where ename != 'BLAKE'
start with ename = 'KING'
connect by prior empno = mgr;
select rpad(' ',level*2) || ename as employee, sal
from emp where ename != 'BLAKE'
start with ename = 'KING'
connect by prior empno = mgr;
문제 284. BLAKE의 팀원들도 전부 안나오게 출력하세요
-> select rpad(' ',level*2)||ename as employee, sal
from emp
start with ename = 'KING'
connect by prior empno = mgr and ename!='BLAKE';
select rpad(' ',level*2)||ename as employee, sal
from emp
start with ename = 'KING'
connect by prior empno = mgr and ename!='BLAKE';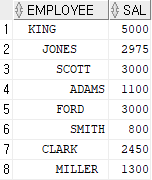
문제 285. 14명의 사원들 전부 출력, 월급이 높은 사원부터 출력
-> select rpad(' ', level*2) || ename as employee, sal
from emp
start with ename = 'KING'
connect by prior empno = mgr
order by sal desc;
select rpad(' ', level*2) || ename as employee, sal
from emp
start with ename = 'KING'
connect by prior empno = mgr
order by sal desc;
문제 286. 위의 서열에 대한 정렬상태 유지, 동시에 월급 높은 순서대로 출력
-> select rpad(' ', level*2) || ename as employee, sal
from emp
start with ename = 'KING'
connect by prior empno = mgr
order siblings by sal desc;

문제 287. 위의 결과에서 앞에 나오는 / 를 잘라내서 출력하세요
-> select ename, ltrim(sys_connect_by_path(ename,'/'),'/') as path
from emp
start with ename = 'KING'
connect by prior empno = mgr;
select ename, ltrim(sys_connect_by_path(ename,'/'),'/') as path
from emp
start with ename = 'KING'
connect by prior empno = mgr;
문제 288. 이름, 월급, 사원 테이블의 최대월급, 사원 테이블의 최소월급
사원테이블의 평균 월급을 출력하세요
-> select ename, sal, (select max(sal) from emp) 최대월급,
(select min(sal) from emp) 최소월급,
(select avg(sal) from emp) 평균월급,
from emp
select ename, sal, (select max(sal) from emp) 최대월급,
(select min(sal) from emp) 최소월급,
(select avg(sal) from emp) 평균월급,
from emp
-> select ename, sal, max(sal) over () 최대월급,
min(sal) over () 최소월급,
round(avg(sal) over ()) 평균월급
from emp;
select ename, sal, max(sal) over () 최대월급,
min(sal) over () 최소월급,
round(avg(sal) over ()) 평균월급
from emp;
문제 289. 아래의 sql을 실행하세요
Select deptno, ename, sal, max(sal) over (partition by deptno) 부서최대
From emp;
Select deptno, ename, sal,
max(sal) over (partition by deptno) 부서최대
From emp;
문제 290. 부서번호, 이름, 월급, 자기가 속한 부서번호의 평균월급을 출력
-> select deptno, ename, sal,
round(avg(sal) over (partition by deptno)) 부서평균
from emp;
select deptno, ename, sal,
round(avg(sal) over (partition by deptno)) 부서평균
from emp;
문제 291. 위의 결과 다시 출력, 자기의 월급이 자기가 속한 부서번호의 평균 월급보다 더 큰 사원만 출력하세요
-> select * from(
select deptno, ename, sal
round(avg(sal) over (partition by deptno)) 부서평균
from emp)
where sal>부서평균;
select * from
(select deptno, ename, sal round(avg(sal) over (partition by deptno)) 부서평균
from emp)
where sal>부서평균;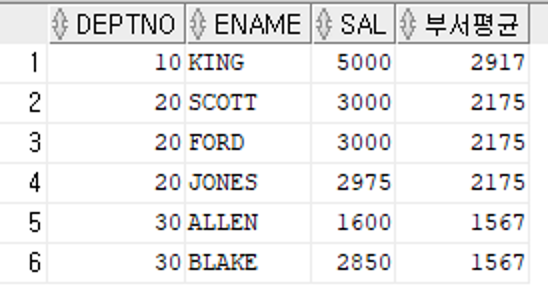
문제 292. 이름 월급, 사원 테이블의 최대 월급, 최소 월급, 토탈 월급을 출력하세요
-> select ename, sal, max(sal) over () 최대월급
, min(sal) over() 최소월급
, sum(sal) over() 토탈월급
from emp;
-> select ename, sal, (select max(sal) from emp) 최대월급,
(select min(sal) from emp) 최소월급,
(select round(sum(sal)) from emp) 토탈월급
from emp;
첫번째 sql은 테이블 참조를 한번만 진행, 그러나 두번째는 4번 조회한다.
실행 시간에 있어 첫번째 sql이 좋은 코드이나, 두번째에서는 where 절을 부가적으로 사용이 가능하기 때문에
사용한다.
문제 294. 연결연산자를 사용해서 하나의 값으로 리턴되게 하세요
select ename, sal, (select max(sal)||min(sal)||sum(sal)
from emp) 전체월급
from emp;
select ename, sal,
(select max(sal)||min(sal)||sum(sal)from emp) 전체월급
from emp;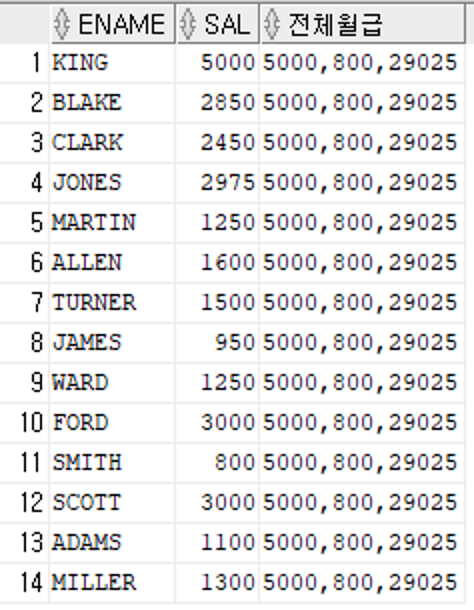
- 튜닝할 때 자주 사용하는 방법
-> 테이블을 여러번 참조하지 않게 하나의 값만 받는 스칼라 서브쿼리절에서 lpad 혹은 rpad를 통해서 간격을
임의로 주고, substr을 함에 따라 컬럼을 나눌 수가 있다.
-> select ename, sal,
substr(전체월급,1,10) 최대월급,
substr(전체월급,11,10) 최소월급,
substr(전체월급,21,10) 토탈월급
from (select ename, sal, (select lpad(max(sal),10,' ')||lpad(min(sal),10,' ')||lpad(sum(sal),10,' ')
from emp) 전체월급
from emp);
select ename, sal,
substr(전체월급,1,10) 최대월급,
substr(전체월급,11,10) 최소월급,
substr(전체월급,21,10) 토탈월급
from (select ename, sal, (select lpad(max(sal),10,' ')||lpad(min(sal),10,' ')||lpad(sum(sal),10,' ') from emp) 전체월급
from emp);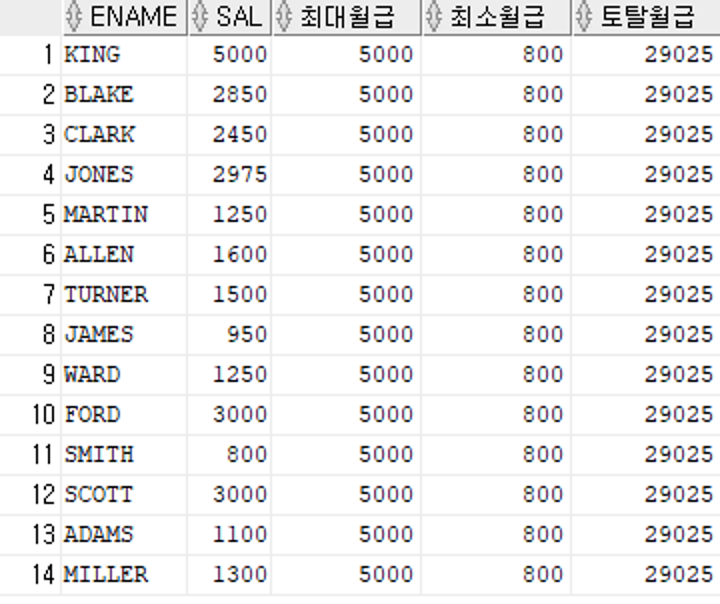
문제 295. 아래의 sql 튜닝하세요
Select e.ename, e.sal, e.deptno, v.평균월급
From emp e, (select deptno, avg(sal) 평균월급
from emp
group by deptno) v
Where e.deptno = v.deptno and e.sal > v.평균월급;
-> select * from
(select deptno, ename, sal, round(avg(sal) over (partition by deptno)) 부서평균
from emp) where sal>부서평균;
-> select * from
(select deptno, ename, sal, round(avg(sal) over (partition by deptno)) 부서평균
from emp) where sal>부서평균;
문제 296. 아래의 sql을 튜닝하시오
Select e.ename, e.job, e.sal, v.직업평균
From emp e, (select job, avg(sal) 직업평균 from emp
group by job) v
Where e.job = v.job and e.sal < v.직업평균;
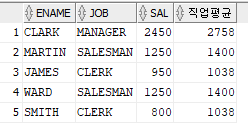
-> select * from(
select ename, job, sal, avg(sal) over (partition by job) 직업평균
from emp) where sal < 직업평균;
select * from(
select ename, job, sal, avg(sal) over (partition by job) 직업평균
from emp) where sal < 직업평균;
문제 297. 아래의 sql을 튜닝하세요
튜닝 전 :
Select job, sum(sal) from emp
Group by job
Union
Select null, sum(sal)
From emp;
튜닝 후 :
-> select job, sum(sal)
from emp
group by rollup(job);
select job, sum(sal)
from emp
group by rollup(job);
문제 298. 아래의 sql을 튜닝하시오
튜닝전 :
Select deptno, job, sum(sal)
From emp
Group by deptno, job
Union all
Select to_number(null) as deptno, job, sum(sal)
From emp
Group by job
Unionall
Select deptno, to_char(null) as job, sum(sal)
From emp
Group by deptno;
튜닝 후:
-> select deptno, job ,sum(sal)
from emp
group by grouping sets((deptno, job), (job), (deptno));
select deptno, job ,sum(sal)
from emp
group by grouping sets((deptno, job), (job), (deptno));
문제 300. 부서번호, 부서번호 별 인원 수 출력, 10번 부서번호의 인원수보다 더 많은 것만 출력
-> select deptno, count(empno)
from emp
group by deptno
having (count(empno)) > (select count(empno) from emp where deptno = 10);
select deptno, count(empno)
from emp
group by deptno
having (count(empno)) > (select count(empno) from emp where deptno = 10);
문제 301. 이름, 직업, 자기 직업의 인원수를 출력하세요
-> select ename,job,
(select count(*) from emp s where s.job = m.job
group by job) 인원수 from emp m;
select ename,job,
(select count(*) from emp s where s.job = m.job
group by job) 인원수
from emp m; 'SQL' 카테고리의 다른 글
| SQL INDEX (0) | 2020.04.21 |
|---|---|
| SQL Table, View (0) | 2020.04.17 |
| SQL Reporting 함수 - Grouping, Exists, Not Exists (0) | 2020.04.13 |
| SQL 서브쿼리, 고급 쿼리문, 집합연산자 (0) | 2020.04.11 |
| SQL JOIN , 서브쿼리 (0) | 2020.04.09 |



